
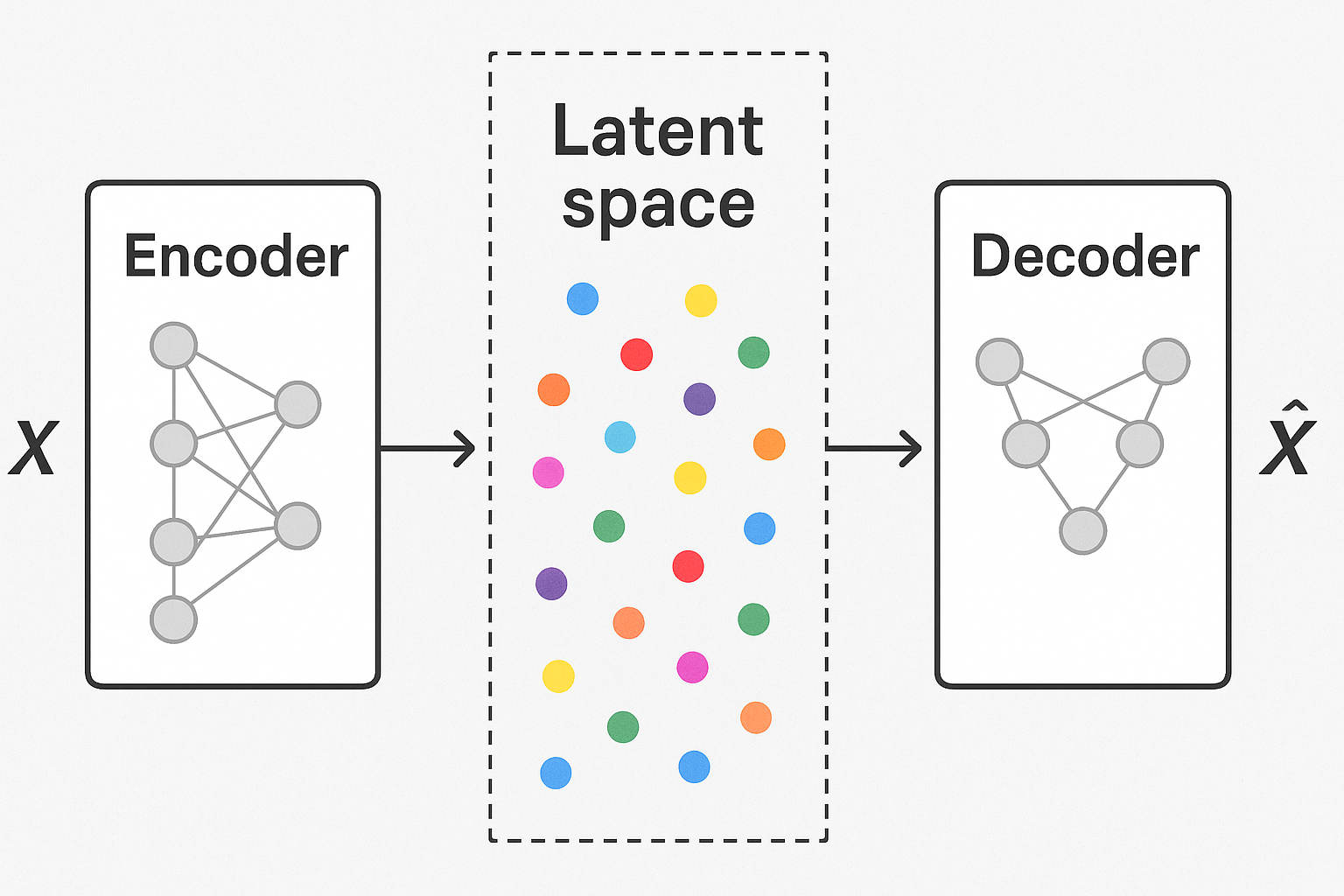
Autoencoders compress data to a bottleneck, then reconstruct. VAEs make the bottleneck probabilistic - encode to a distribution, sample from it, decode. This enables generation of new data.
Regular autoencoder
Encoder: x → z (deterministic) Decoder: z → x̂ (deterministic)
Problem: latent space is sparse, unstructured. Can’t sample meaningful z.
VAE idea
Encoder: x → (μ, σ) (parameters of distribution) Sample: z ~ N(μ, σ²) Decoder: z → x̂
Latent space becomes continuous. Similar inputs → similar latent distributions.
Interactive demo: VAE Animation
The loss function
$$\mathcal{L} = \mathbb{E}{z \sim q(z|x)}[\log p(x|z)] - D{KL}(q(z|x) | p(z))$$
Two parts:
- Reconstruction: Decoded output matches input
- KL divergence: Latent distribution close to prior (standard normal)
def vae_loss(x, x_recon, mu, logvar):
# Reconstruction loss
recon_loss = F.binary_cross_entropy(x_recon, x, reduction='sum')
# KL divergence: -0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl_loss
Reparameterization trick
Problem: can’t backprop through sampling.
Solution: separate randomness from parameters.
$$z = \mu + \sigma \cdot \epsilon, \quad \epsilon \sim N(0, 1)$$
Now gradient flows through μ and σ.
def reparameterize(mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
Architecture
class VAE(nn.Module):
def __init__(self, input_dim, latent_dim):
super().__init__()
# Encoder
self.encoder = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.fc_mu = nn.Linear(256, latent_dim)
self.fc_var = nn.Linear(256, latent_dim)
# Decoder
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, input_dim),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_var(h)
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = reparameterize(mu, logvar)
return self.decode(z), mu, logvar
Generating new samples
# Sample from prior
z = torch.randn(num_samples, latent_dim)
generated = model.decode(z)
Interpolation
VAE latent space is smooth. Interpolate between two images:
z1 = model.encode(img1)[0] # get mu
z2 = model.encode(img2)[0]
for alpha in np.linspace(0, 1, 10):
z_interp = alpha * z1 + (1 - alpha) * z2
img_interp = model.decode(z_interp)
β-VAE
Weight the KL term:
$$\mathcal{L} = \text{recon} + \beta \cdot \text{KL}$$
Higher β → more disentangled latent dimensions (each captures different factor).
Limitations
- Blurry outputs (mean of possibilities)
- KL collapse (posterior = prior, ignores input)
- Harder to train than GANs
Improvements: VQ-VAE (discrete latent), hierarchical VAE, diffusion models…
VAEs make sense now? Support ML Animations with a star and share this with generative model enthusiasts!


