
The paper that changed everything: “Attention Is All You Need” (2017). The authors threw out RNNs, threw out convolutions, and built a model using only attention. That architecture now powers GPT, BERT, Claude, and virtually every modern language model.
Let’s break down how it actually works.
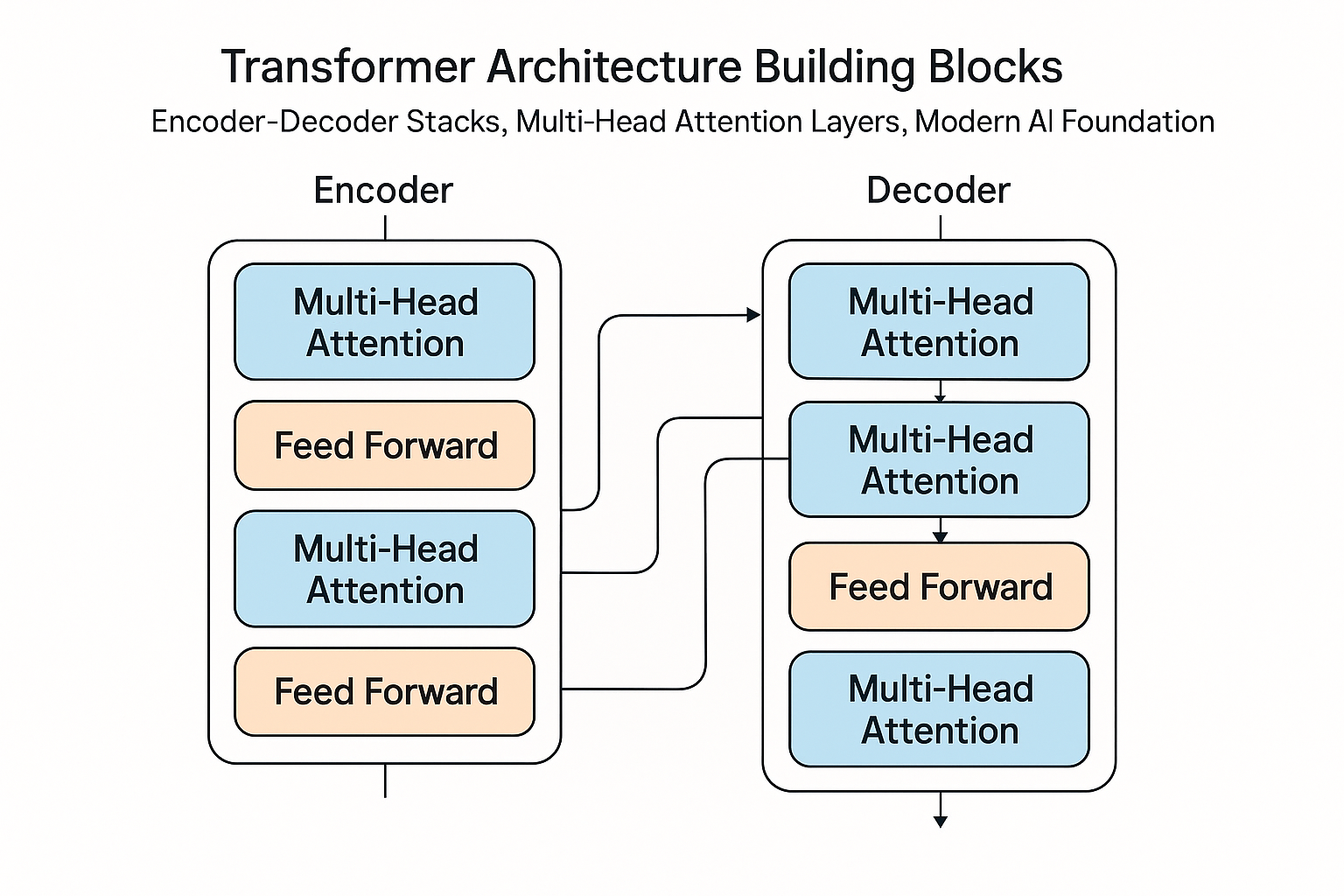
The big picture
The original transformer has two main parts:
- Encoder: Reads the input and creates rich representations
- Decoder: Generates output, one token at a time, while looking at the encoder’s representations
Here’s the thing though - modern models often use just one half:
- BERT = encoder only (good for understanding text)
- GPT = decoder only (good for generating text)
Interactive demo: Transformer Animation - click through each component to see how data flows.
Inside an encoder block
Each encoder layer does four things:
- Multi-head self-attention - every position attends to every other position
- Add & normalize - residual connection + layer normalization
- Feed-forward network - process each position independently
- Add & normalize - another residual + layer norm
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Linear(d_ff, d_model)
)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x):
# Pre-norm style (more common now)
x = x + self.attention(self.norm1(x))
x = x + self.ffn(self.norm2(x))
return x
Stack 6 to 96 of these (depending on how big your model is) and you’ve got an encoder!
Inside a decoder block
The decoder is similar to the encoder, but with two key differences:
- Masked self-attention: When generating token 5, you can only see tokens 1-4, not the future
- Cross-attention: After self-attention, attend to the encoder’s output
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.cross_attention = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(...)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, x, encoder_output, mask):
x = x + self.self_attention(self.norm1(x), mask=mask)
x = x + self.cross_attention(self.norm2(x), encoder_output)
x = x + self.ffn(self.norm3(x))
return x
Feed-forward network
Simple but crucial. Processes each position independently:
$$\text{FFN}(x) = \text{GELU}(xW_1 + b_1)W_2 + b_2$$
Typically d_ff = 4 × d_model. This is where most parameters live.
Recent theory: FFN acts as key-value memory. First layer selects patterns, second retrieves information.
Attention patterns
Multi-head attention lets model learn different relationship types:
- Head 1: syntactic dependencies
- Head 2: coreference
- Head 3: positional patterns
- etc.
Different heads specialize automatically during training.
Residual connections
Every sublayer has skip connection:
$$\text{output} = \text{sublayer}(x) + x$$
Critical for:
- Training deep networks (gradient flow)
- Preserving information
- Allowing layers to learn “refinements”
The full picture
Input Embeddings + Positional Encoding
↓
┌──────────────────────────┐
│ Encoder Block ×N │
│ - Self-attention │
│ - FFN │
└──────────────────────────┘
↓
Encoder Output
↓
┌──────────────────────────┐
│ Decoder Block ×N │
│ - Masked self-attention │
│ - Cross-attention │
│ - FFN │
└──────────────────────────┘
↓
Linear + Softmax
↓
Output Tokens
Variants
Encoder-only (BERT): Classification, understanding tasks Decoder-only (GPT): Generation, language modeling Encoder-decoder (T5): Translation, summarization
Modern trend: decoder-only scales best, most versatile.
Transformers decoded! Star ML Animations and share this architecture breakdown with your ML community!


