
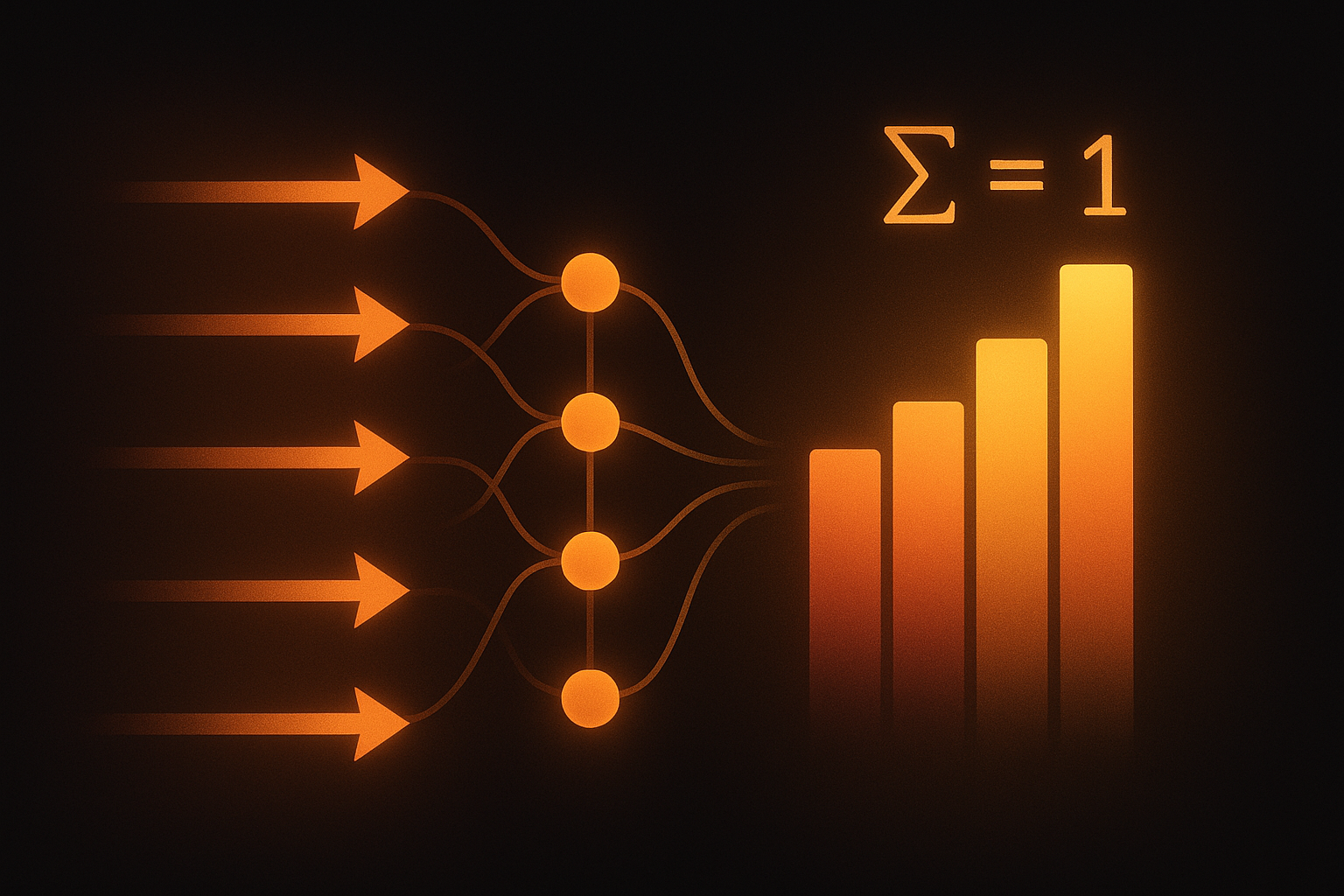
Neural network outputs raw numbers called “logits.” These could be anything: -500, 2.3, 47. For classification, we need probabilities between 0 and 1 that sum to 1. Softmax does exactly that conversion.
The formula
Given a vector z of logits:
$$\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}$$
In plain English: take e^(each value), then divide by the total. Now everything is positive and sums to 1!
def softmax(z):
exp_z = np.exp(z)
return exp_z / exp_z.sum()
logits = [2.0, 1.0, 0.1]
probs = softmax(logits) # [0.659, 0.242, 0.099]
Interactive demo: Softmax Animation - drag the logits around and watch the probabilities change.
What softmax actually does
Let’s build intuition:
- Bigger logit → higher probability (the exponential amplifies differences)
- Negative logit → small probability (but never zero!)
- Ranking preserved - if logit A > logit B, then prob(A) > prob(B)
- All outputs in [0, 1] and they always sum to 1
Think of it as a “soft” version of argmax. Instead of picking one winner, it gives each option a score proportional to how much “bigger” it is.
Why use exponential?
We need a function that:
- Makes all numbers positive
- Preserves which one is biggest
- Is smooth and differentiable
Exponential nails all three. Plus it has nice mathematical properties that make gradients clean.
Watch out: numerical stability!
Here’s a trap:
logits = [1000, 1001, 1002]
np.exp(logits) # [inf, inf, inf] - overflow!
The fix is simple - subtract the max first:
def stable_softmax(z):
z = z - np.max(z) # now max is 0
exp_z = np.exp(z)
return exp_z / exp_z.sum()
This doesn’t change the result (the subtraction cancels out), but exp() never sees a number > 0. No overflow.
Good news: PyTorch and TensorFlow handle this automatically.
Temperature: controlling confidence
Want sharper or softer probabilities? Add temperature:
$$\text{softmax}(z_i, T) = \frac{e^{z_i/T}}{\sum_j e^{z_j/T}}$$
| Temperature | Effect |
|---|---|
| T = 1 | Normal softmax |
| T < 1 | Sharper, more confident (winner takes more) |
| T > 1 | Softer, more uniform (spread out) |
| T → 0 | Becomes argmax (one-hot) |
| T → ∞ | Becomes uniform |
def softmax_with_temp(z, temperature=1.0):
z = z / temperature
return stable_softmax(z)
You’ll see temperature in:
- Knowledge distillation - soft labels from teacher model
- Text generation - controlling randomness (higher T = more creative)
- Attention - sometimes used to sharpen focus
Softmax vs other activations
Softmax - multiclass classification output Sigmoid - binary classification or multi-label ReLU - hidden layers
Softmax is for output layer when you have mutually exclusive classes.
With cross-entropy loss
Almost always used together:
$$L = -\sum_i y_i \log(\text{softmax}(z_i))$$
Mathematically: $$\frac{\partial L}{\partial z_i} = \text{softmax}(z_i) - y_i$$
Beautiful gradient. Just predicted minus actual.
In code, use combined function:
# PyTorch - these are equivalent but second is more stable
loss1 = nn.CrossEntropyLoss()(logits, targets)
loss2 = nn.NLLLoss()(F.log_softmax(logits), targets)
Log softmax
Often want log of softmax probabilities:
$$\log\text{softmax}(z_i) = z_i - \log\sum_j e^{z_j}$$
More numerically stable than log(softmax(z)).
# Bad - can get log(0) = -inf
log_probs = np.log(softmax(z))
# Good
log_probs = F.log_softmax(z, dim=-1)
Softmax in attention
Attention scores use softmax:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Converts similarity scores to attention weights that sum to 1.
Common confusions
“Softmax regression” = logistic regression for multiclass. The model is linear, softmax just converts to probabilities.
Independent vs mutually exclusive:
- Mutually exclusive classes (cat OR dog) → softmax
- Independent labels (has_cat AND has_dog) → sigmoid per label
Now you get softmax! Drop a star on ML Animations and share this with your study group!


