
RNNs have short memory. Information from early timesteps fades quickly. LSTMs fix this with gates that control information flow.
Before transformers dominated, LSTM was the go-to for sequence tasks.
The vanilla RNN problem
Simple RNN: $$h_t = \tanh(W_h h_{t-1} + W_x x_t)$$
Information from step 0 must pass through all intermediate steps to reach step 100. It gets multiplied by weights each time.
If weights < 1: vanishing gradients If weights > 1: exploding gradients
Long sequences = trouble.
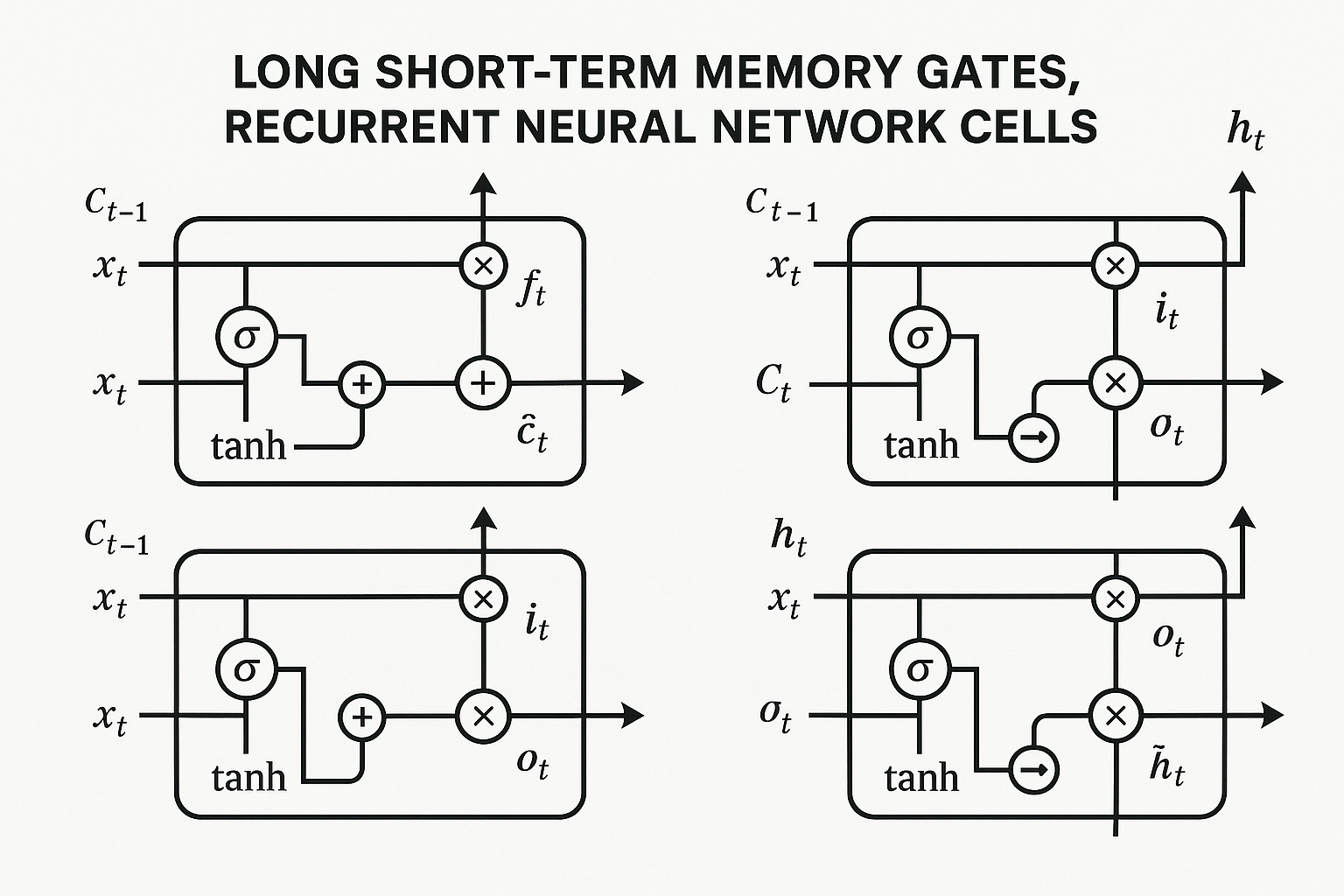
LSTM architecture
LSTM adds a “cell state” - a highway for information to flow unimpeded.
Four gates control what happens:
Interactive demo: LSTM Animation
Forget gate
Decides what to throw away from cell state.
$$f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)$$
Output: 0 = forget completely, 1 = keep everything
Input gate
Decides what new information to store.
$$i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)$$ $$\tilde{C}t = \tanh(W_C \cdot [h{t-1}, x_t] + b_C)$$
Cell state update
Combine forget and input:
$$C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t$$
Old cell state (maybe partially forgotten) + new information (maybe partially added)
Output gate
Decides what to output based on cell state.
$$o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)$$ $$h_t = o_t \odot \tanh(C_t)$$
Why it works
Cell state C can flow unchanged across many timesteps (if forget gate ≈ 1 and input gate ≈ 0).
Gradients flow through the cell state without repeated multiplication by small numbers.
Information from step 0 can reach step 100 if the network learns to keep forget gate open.
Code
PyTorch makes it simple:
lstm = nn.LSTM(
input_size=100,
hidden_size=256,
num_layers=2,
batch_first=True,
dropout=0.1,
bidirectional=True
)
# Forward pass
output, (h_n, c_n) = lstm(x)
# output: [batch, seq_len, hidden_size * num_directions]
# h_n: final hidden state
# c_n: final cell state
Bidirectional LSTM
Process sequence in both directions. For tasks where full context available (not generation).
lstm = nn.LSTM(..., bidirectional=True)
# hidden_size doubles (forward + backward)
Often helps for classification, tagging, etc.
GRU - simplified variant
Gated Recurrent Unit. Similar idea, fewer parameters.
Two gates instead of four:
- Reset gate
- Update gate
Faster to train, often similar performance.
LSTMs finally make sense? Star ML Animations and share this guide with anyone learning sequence modeling!


