
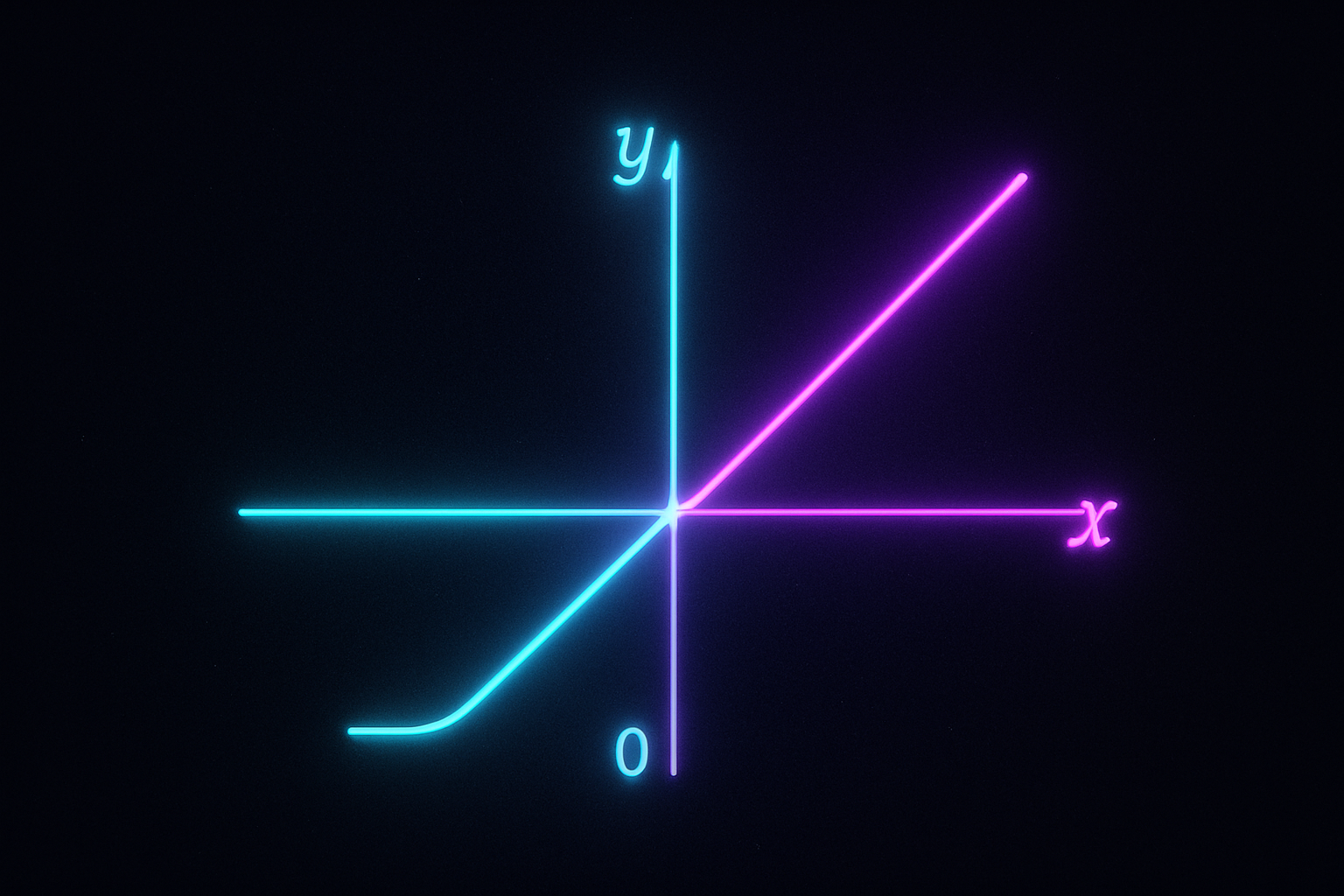
ReLU is great but has a problem. Neurons can die. Leaky ReLU fixes this with one small change.
The dead neuron problem
Regular ReLU: if input is negative, output is 0. Gradient is also 0.
If a neuron always gets negative inputs, it never updates. It’s dead.
This happens more than you’d think. Bad initialization, high learning rate, certain data distributions… suddenly 30% of your network is doing nothing.
Leaky ReLU solution
Instead of zero for negatives, use small slope:
$$f(x) = \begin{cases} x & x > 0 \ \alpha x & x \leq 0 \end{cases}$$
Usually α = 0.01
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
Interactive demo: Leaky ReLU Animation
Why it works
Negative inputs now have small gradient (α instead of 0). Even if neuron mostly outputs negative values, it can still learn.
Dead neurons can “come back to life.”
The gradient
$$\frac{df}{dx} = \begin{cases} 1 & x > 0 \ \alpha & x \leq 0 \end{cases}$$
Never zero (assuming α ≠ 0). Gradient always flows.
Choosing alpha
0.01 - common default, works well
0.1-0.3 - more aggressive, some papers suggest this
Learned (PReLU) - let network decide
# PyTorch
nn.LeakyReLU(negative_slope=0.01)
nn.LeakyReLU(negative_slope=0.2)
# PReLU - alpha is learned
nn.PReLU()
PReLU - Parametric ReLU
Make alpha a learnable parameter:
class PReLU(nn.Module):
def __init__(self, num_channels):
super().__init__()
self.alpha = nn.Parameter(torch.ones(num_channels) * 0.25)
def forward(self, x):
return torch.where(x > 0, x, self.alpha * x)
Each channel can have different alpha. Network learns what works.
He et al. (2015) showed PReLU helps especially in deep networks.
Does it actually matter?
Honest answer: often not much difference for typical networks.
When it does matter:
- Very deep networks
- High learning rates
- Small batch sizes
- Networks with lots of dead neurons
Easy to check: monitor activation statistics during training.
# quick check for dead neurons
activations = relu(layer_output)
dead_ratio = (activations == 0).float().mean()
print(f"Dead neuron ratio: {dead_ratio:.2%}")
If you see high dead ratios, try Leaky ReLU.
Code comparison
import torch
import torch.nn as nn
# With ReLU
model_relu = nn.Sequential(
nn.Linear(100, 50),
nn.ReLU(),
nn.Linear(50, 10)
)
# With Leaky ReLU
model_leaky = nn.Sequential(
nn.Linear(100, 50),
nn.LeakyReLU(0.01),
nn.Linear(50, 10)
)
# With PReLU
model_prelu = nn.Sequential(
nn.Linear(100, 50),
nn.PReLU(),
nn.Linear(50, 10)
)
My recommendation
Start with ReLU. It’s the default for good reason.
If you notice:
- Training stalls early
- Many neurons outputting constant 0
- Gradient problems
Switch to Leaky ReLU. Usually solves it.
PReLU if you want to squeeze out a bit more performance and have compute to spare.
These activation function animations made the concept clear? Support ML Animations with a ⭐ and share on social!


