
Word2Vec problem: what about misspellings? What about “unhappiness” when you only trained on “happy”? What about German compound words?
FastText fixes this by using subword information. Facebook AI released it in 2016.
The core idea
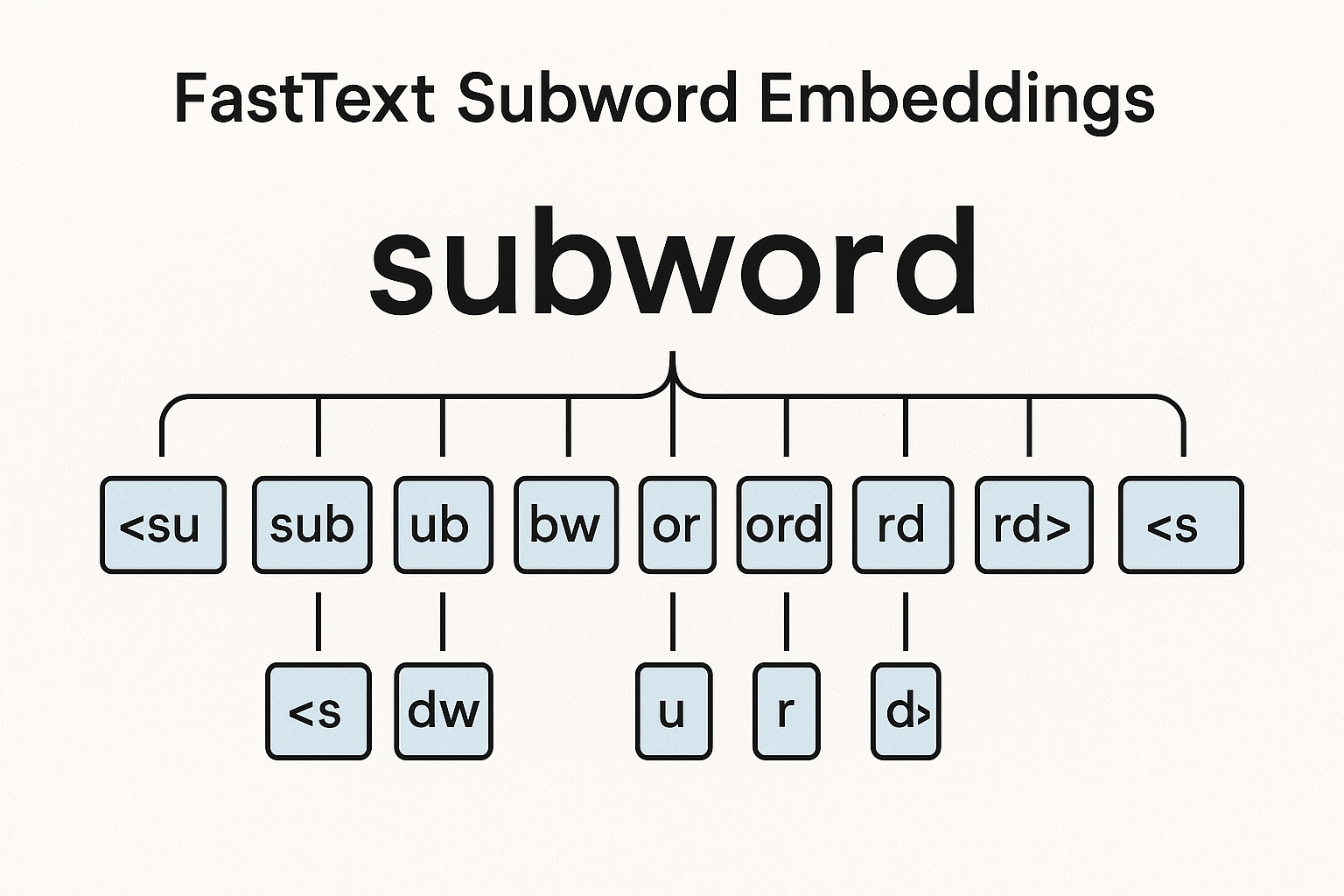
Instead of one vector per word, break words into character n-grams.
“where” with n=3:
- “<wh”, “whe”, “her”, “ere”, “re>”
- Plus the word itself: “”
Word vector = sum of all its n-gram vectors.
def get_ngrams(word, min_n=3, max_n=6):
word = '<' + word + '>' # boundary markers
ngrams = []
for n in range(min_n, max_n + 1):
for i in range(len(word) - n + 1):
ngrams.append(word[i:i+n])
return ngrams
get_ngrams('cat')
# ['<ca', 'cat', 'at>', '<cat', 'cat>', '<cat>']
Interactive demo: FastText Animation
Why this works for OOV
Never seen “unhappyness” (misspelled)?
Break it into n-grams. Some of those n-grams appeared in:
- “happy”
- “unhappy”
- “happiness”
- “sadness”
The vector is constructed from n-grams the model has seen. Not perfect but way better than nothing.
Practical advantages
Morphologically rich languages
Finnish, Turkish, German… words have many forms. FastText handles this naturally because related forms share n-grams.
“playing”, “played”, “plays” all share “play” n-grams.
Typos and variations
“learning”, “leanring”, “lerning” will have similar vectors.
Rare words
Word appearing once? In Word2Vec, vector is garbage. In FastText, n-grams have been seen in other words.
Using FastText
Official library:
import fasttext
# train
model = fasttext.train_unsupervised(
'data.txt',
model='skipgram', # or 'cbow'
dim=100,
minn=3, # min n-gram
maxn=6, # max n-gram
)
# get vector (works for any word!)
vec = model.get_word_vector('somemadeupword')
# similar words
model.get_nearest_neighbors('cat')
With Gensim:
from gensim.models import FastText
model = FastText(
sentences,
vector_size=100,
window=5,
min_count=1,
min_n=3,
max_n=6,
)
Pretrained vectors
FastText released vectors for 157 languages. Trained on Wikipedia + Common Crawl.
FastText clicked? Help the community by starring ML Animations and sharing on Twitter or LinkedIn!


