
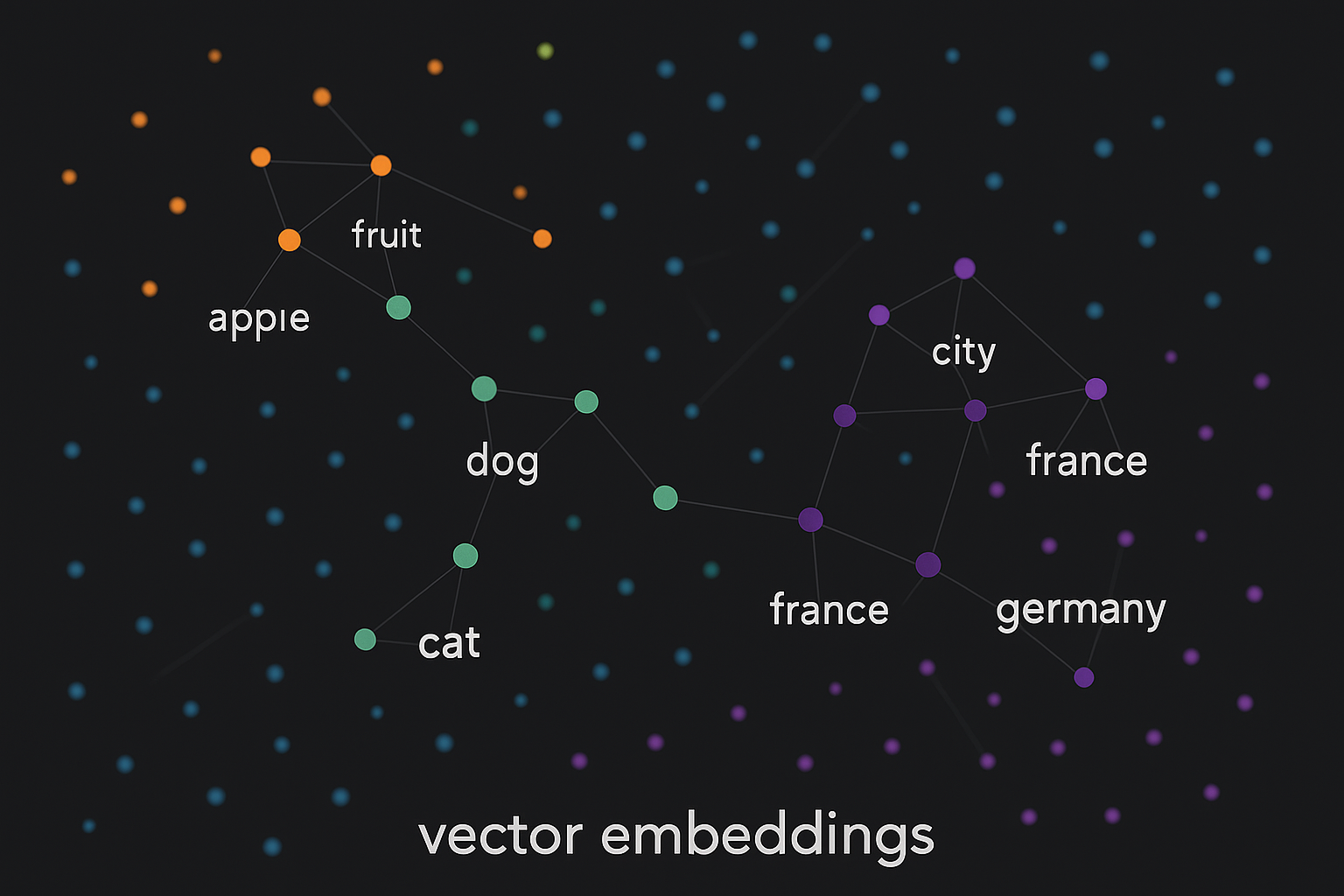
Embeddings are everywhere in modern ML. Words, sentences, images, users, products, songs… anything can become an embedding. But what are they actually, and why do we need them?
The core idea
An embedding converts something discrete (like a word) into a list of numbers (a vector) where similar things end up close together.
Cat → [0.2, -0.5, 0.8, ...]
Dog → [0.3, -0.4, 0.7, ...]
Car → [-0.8, 0.3, -0.2, ...]
Cat and dog vectors are close to each other (both are pets). Car is far from both. The embedding has captured meaning!
Interactive demo: Embeddings Animation - see how similar items cluster together in embedding space.
Why not just use one-hot encoding?
The naive approach - one-hot encoding:
cat = [1, 0, 0, 0, ...] # 10,000 dims for 10,000 word vocabulary
dog = [0, 1, 0, 0, ...]
car = [0, 0, 1, 0, ...]
This has serious problems:
- Huge vectors - vocabulary of 50k words = 50k dimensions
- All words equally distant - “cat” is as far from “dog” as from “refrigerator”
- No semantic meaning - the model can’t see that cat and dog are related
- Wasteful - 99.99% zeros
Embeddings solve ALL of these. You get dense 100-1000 dimensional vectors that capture meaning.
Word embeddings: where it started
Word2Vec, GloVe, and FastText showed the world that embeddings work. The key insight: words appearing in similar contexts have similar meanings.
“The ___ sat on the mat” → probably cat, dog, baby, etc.
Training on billions of sentences, the model learns that these words should have similar vectors.
from gensim.models import Word2Vec
# Similar words cluster together
model.wv.most_similar('king')
# [('queen', 0.8), ('prince', 0.7), ('monarch', 0.6), ...]
The famous limitation: one vector per word. “Bank” (river) and “bank” (financial institution) get the same embedding. Context-aware models like BERT fix this.
Sentence and document embeddings
Individual words are great, but often you need to represent entire sentences or documents.
Simple approach: average the word vectors
sentence_vec = np.mean([word_vec(w) for w in sentence])
Works okay for some tasks, but loses word order completely. “Dog bites man” = “Man bites dog” - not ideal!
Better approach: models trained specifically for sentence similarity
- Sentence-BERT
- Universal Sentence Encoder
- E5, BGE (recent and good)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(['This is sentence one', 'Another sentence'])
Contextual embeddings
BERT and friends give different vectors based on context.
“I sat by the river bank” → bank_vector_1 “I went to the bank to deposit money” → bank_vector_2
Different vectors! Context matters.
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('bert-base-uncased')
# each token gets context-dependent vector
outputs = model(**tokenizer("hello world", return_tensors='pt'))
embeddings = outputs.last_hidden_state # [1, seq_len, 768]
Image embeddings
CNN or Vision Transformer extracts features. Last layer before classification head = image embedding.
from torchvision.models import resnet50
model = resnet50(pretrained=True)
# remove classification head
model = torch.nn.Sequential(*list(model.children())[:-1])
# image → 2048-dim vector
embedding = model(image).squeeze()
Or use CLIP for multi-modal embeddings (images and text in same space).
Using embeddings
Similarity search
Find nearest neighbors in embedding space.
from sklearn.metrics.pairwise import cosine_similarity
# find most similar to query
similarities = cosine_similarity([query_emb], all_embeddings)
top_k = np.argsort(similarities[0])[-k:]
Clustering
Group similar items.
from sklearn.cluster import KMeans
clusters = KMeans(n_clusters=10).fit_predict(embeddings)
Embeddings make sense now? Give ML Animations a star ⭐ and share this post with your ML friends!


