
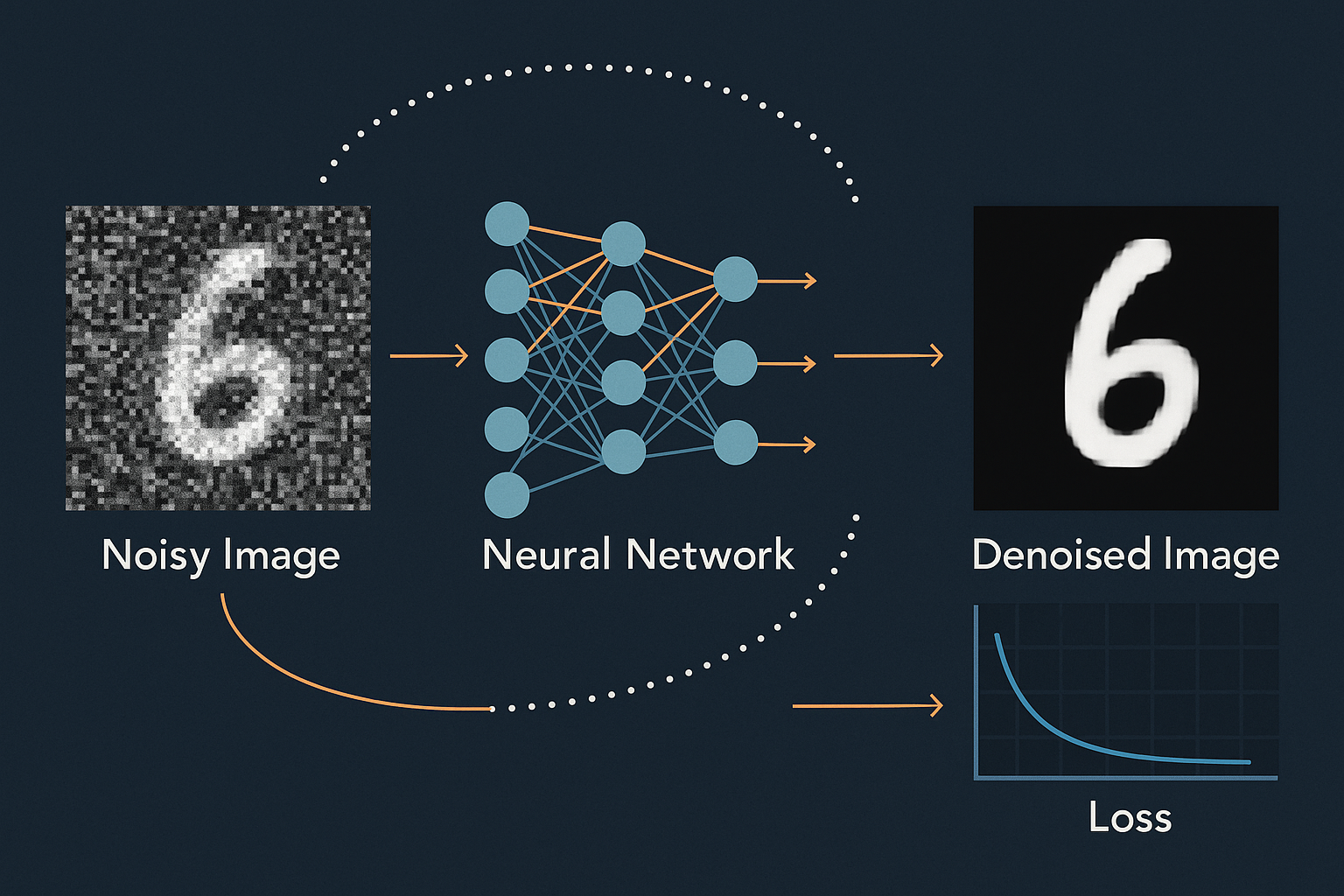
The denoiser needs to see both big picture and fine details. U-Net does this: encode down (context), decode up (details), skip connections (preserve information).
Part 4 of 7 in the Diffusion Models series.
U-Net structure
Input (3, 256, 256)
↓ conv
(64, 256, 256) ──────────────────────────→ concat
↓ down
(128, 128, 128) ─────────────────────→ concat
↓ down
(256, 64, 64) ──────────────────→ concat
↓ down
(512, 32, 32) ─────────────→ concat
↓ down
(512, 16, 16) │
↓ middle │
(512, 16, 16) │
↓ up │
(512, 32, 32) ←────────────┘
↓ up
(256, 64, 64) ←─────────────────┘
↓ up
(128, 128, 128) ←────────────────────┘
↓ up
(64, 256, 256) ←─────────────────────────┘
↓ conv
Output (3, 256, 256)
Interactive demo: DiT Animation
Timestep conditioning
Network needs to know: “How noisy is this input?”
Embed timestep as vector, add to features:
class TimestepEmbedding(nn.Module):
def __init__(self, dim):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(dim, dim * 4),
nn.SiLU(),
nn.Linear(dim * 4, dim)
)
def forward(self, t):
# Sinusoidal embedding (like positional encoding)
half_dim = self.dim // 2
emb = math.log(10000) / half_dim
emb = torch.exp(torch.arange(half_dim) * -emb)
emb = t[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
return self.mlp(emb)
Residual block with timestep
class ResBlock(nn.Module):
def __init__(self, in_ch, out_ch, time_emb_dim):
super().__init__()
self.conv1 = nn.Conv2d(in_ch, out_ch, 3, padding=1)
self.conv2 = nn.Conv2d(out_ch, out_ch, 3, padding=1)
self.norm1 = nn.GroupNorm(8, out_ch)
self.norm2 = nn.GroupNorm(8, out_ch)
self.time_mlp = nn.Linear(time_emb_dim, out_ch)
if in_ch != out_ch:
self.skip = nn.Conv2d(in_ch, out_ch, 1)
else:
self.skip = nn.Identity()
def forward(self, x, t_emb):
h = self.norm1(F.silu(self.conv1(x)))
# Add timestep info
h = h + self.time_mlp(t_emb)[:, :, None, None]
h = self.norm2(F.silu(self.conv2(h)))
return h + self.skip(x)
Attention layers
At low resolution, add self-attention. Captures global dependencies:
class AttentionBlock(nn.Module):
def __init__(self, channels):
super().__init__()
self.norm = nn.GroupNorm(8, channels)
self.qkv = nn.Conv2d(channels, channels * 3, 1)
self.proj = nn.Conv2d(channels, channels, 1)
def forward(self, x):
B, C, H, W = x.shape
h = self.norm(x)
qkv = self.qkv(h).reshape(B, 3, C, H*W)
q, k, v = qkv[:, 0], qkv[:, 1], qkv[:, 2]
attn = torch.softmax(q.transpose(-1, -2) @ k / math.sqrt(C), dim=-1)
h = (v @ attn.transpose(-1, -2)).reshape(B, C, H, W)
return x + self.proj(h)
Simplified U-Net
class UNet(nn.Module):
def __init__(self):
super().__init__()
# Time embedding
self.time_emb = TimestepEmbedding(256)
# Encoder
self.enc1 = ResBlock(3, 64, 256)
self.enc2 = ResBlock(64, 128, 256)
self.enc3 = ResBlock(128, 256, 256)
self.down = nn.MaxPool2d(2)
# Middle
self.mid = ResBlock(256, 256, 256)
self.mid_attn = AttentionBlock(256)
# Decoder
self.up = nn.Upsample(scale_factor=2)
self.dec3 = ResBlock(512, 128, 256) # 256 + 256 from skip
self.dec2 = ResBlock(256, 64, 256)
self.dec1 = ResBlock(128, 64, 256)
self.out = nn.Conv2d(64, 3, 1)
def forward(self, x, t):
t_emb = self.time_emb(t)
# Encode
e1 = self.enc1(x, t_emb)
e2 = self.enc2(self.down(e1), t_emb)
e3 = self.enc3(self.down(e2), t_emb)
# Middle
m = self.mid_attn(self.mid(self.down(e3), t_emb))
# Decode with skip connections
d3 = self.dec3(torch.cat([self.up(m), e3], dim=1), t_emb)
d2 = self.dec2(torch.cat([self.up(d3), e2], dim=1), t_emb)
d1 = self.dec1(torch.cat([self.up(d2), e1], dim=1), t_emb)
return self.out(d1)
Key design choices
- Group norm everywhere
- SiLU activations
- Attention only at low resolution (expensive)
- Skip connections concatenate (not add)
- Timestep added to every block
U-Net architecture for diffusion explained! Support ML Animations with a star and share this series with your AI art community!


