
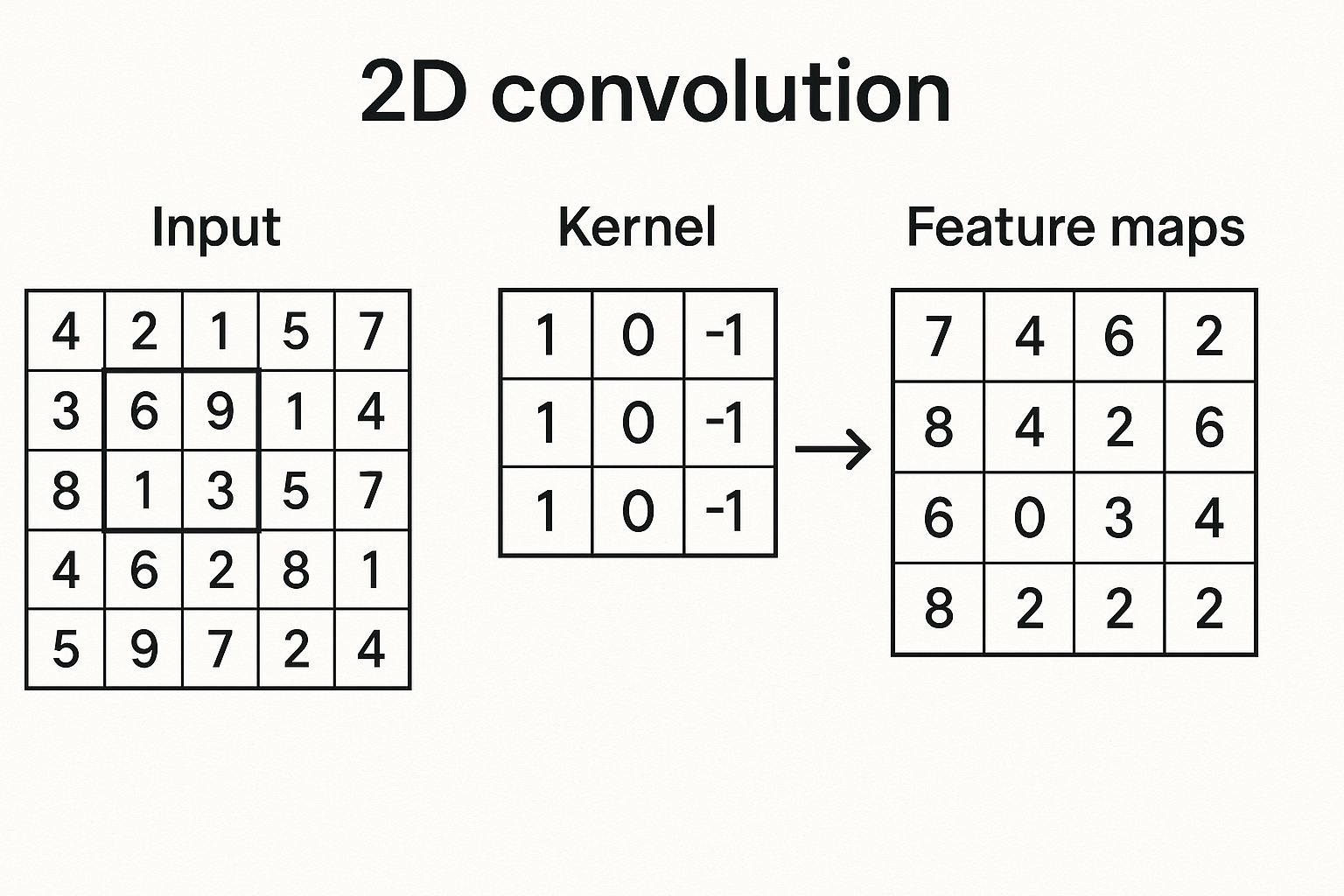
Images are grids of pixels. Fully connected layers would need billions of parameters. Convolutions exploit spatial structure - nearby pixels are related.
What is convolution?
Slide a small filter (kernel) across the image. At each position, compute dot product between filter and image patch.
Image patch: Filter: Output:
1 2 3 1 0 1 1*1 + 2*0 + 3*1 +
4 5 6 * 0 1 0 = 4*0 + 5*1 + 6*0 + = 15
7 8 9 1 0 1 7*1 + 8*0 + 9*1
The filter “detects” certain patterns - edges, textures, shapes.
Interactive demo: Conv2D Animation
Key concepts
Kernel size: Typically 3x3, 5x5, 7x7. Larger = bigger receptive field but more parameters.
Stride: How many pixels to move between positions. Stride 2 halves spatial dimensions.
Padding: Add zeros around edges. “Same” padding keeps dimensions unchanged.
Channels: Input has channels (RGB = 3), output has as many as there are filters.
The math
For input I of shape (H, W, C_in) and kernel K of shape (k, k, C_in, C_out):
$$O_{x,y,c} = \sum_{i=0}^{k-1}\sum_{j=0}^{k-1}\sum_{c’=0}^{C_{in}-1} I_{x+i, y+j, c’} \cdot K_{i,j,c’,c}$$
Why convolutions work
Parameter sharing: Same filter applied everywhere. Edge detector at top-left works at bottom-right too.
Translation equivariance: Shift input → output shifts same amount. Position doesn’t matter for pattern detection.
Local connectivity: Each output depends only on small region. Matches image structure.
Building a CNN
import torch.nn as nn
model = nn.Sequential(
# Conv block 1
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2), # 32x32 → 16x16
# Conv block 2
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2), # 16x16 → 8x8
# Flatten and classify
nn.Flatten(),
nn.Linear(64 * 8 * 8, 10)
)
Pooling
Reduce spatial dimensions. Makes representation more compact and invariant.
Max pooling: Take maximum value in each window
Average pooling: Take average value
nn.MaxPool2d(kernel_size=2, stride=2) # halves dimensions
nn.AvgPool2d(kernel_size=2, stride=2)
Global pooling: pool entire spatial dimension to 1x1
nn.AdaptiveAvgPool2d((1, 1)) # any input → 1x1 output
Output size calculation
$$O = \frac{I - K + 2P}{S} + 1$$
Where:
- I = input size
- K = kernel size
- P = padding
- S = stride
Example: input 32, kernel 3, padding 1, stride 1: $$O = \frac{32 - 3 + 2}{1} + 1 = 32$$
Same padding keeps size. Stride 2 halves it.
1x1 Convolutions
Filter size 1x1. Seems useless but:
- Changes number of channels
- Adds nonlinearity (with activation)
- Reduces computation
Used in ResNet bottleneck blocks, Inception, etc.
nn.Conv2d(256, 64, kernel_size=1) # reduce channels
nn.Conv2d(64, 256, kernel_size=1) # expand back
Convolutions make sense now? Star ML Animations and share this visual guide with your deep learning community!


